ERNIE-SAT 模型
ERNIE-SAT
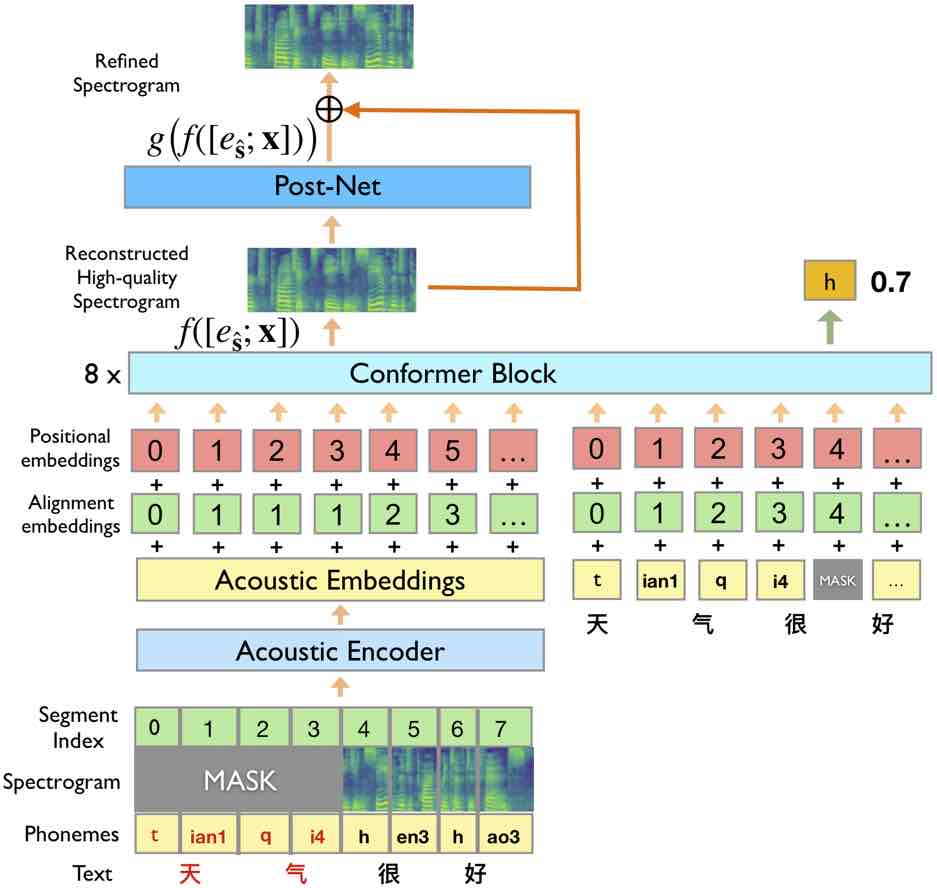
ERNIE-SAT类别文心·跨模态大模型应用语音编辑、语音生成、语音克隆、带语音克隆的语音到语音翻译模型概述ERNIE-SAT 采用语音-文本联合训练的方式在中文和英文数据集上进行预训练。使得模型学到了语音和文本的对齐关系,并且生成频谱的精度更高,合成声音的质量更高。模型说明模型概述现有的语音预训练相关工作在许多语音理解相关方向任务效果上提升显著,如语音识别、语音分类和语音-文本翻译等。
-
*.2折
官方价格:咨询
-
*.2折
官方价格:咨询
-
*.2折
官方价格:咨询
ERNIE-SAT
类别文心·跨模态大模型
应用语音编辑、语音生成、语音克隆、带语音克隆的语音到语音翻译
模型概述
ERNIE-SAT 采用语音-文本联合训练的方式在中文和英文数据集上进行预训练。使得模型学到了语音和文本的对齐关系,并且生成频谱的精度更高,合成声音的质量更高。
模型说明
模型概述
现有的语音预训练相关工作在许多语音理解相关方向任务效果上提升显著,如语音识别、语音分类和语音-文本翻译等。但对于语音合成,生成高质量语音仍然具有挑战性。
ERNIE-SAT 采用语音-文本联合训练的方式在中文和英文数据集上进行预训练。使得模型学到了语音和文本的对齐关系,并且生成频谱的精度更高,合成声音的质量更高。
原理介绍
ERNIE-SAT 是语音-语言跨模态大模型,可以处理中文和英文。采用语言和语音联合掩码进行预训练,融合跨语言音素知识,实现语音和文本的对齐关系。有效提升了多种语音合成任务的效果。

模型效果
| 其他方法 | ERNIE-SAT | |
|---|---|---|
| 语音编辑 | 3.58 | 3.65 |
| 多人声语音合成 | 3.85 | 3.94 |
| 跨语言语音克隆 | 3.49 | 3.58 |
应用场景
针对语音编辑、语音生成、语音克隆、带语音克隆的语音到语音翻译等任务
使用方案
通过 ERNIEKit(开源版)使用
1.安装飞桨与环境依赖
本项目的代码基于 Paddle(version>=2.0)
本项目开放提供加载 torch 版本的 vocoder 的功能
torch version>=1.8
安装 htk: 在官方地址注册完成后,即可进行下载较新版本的 htk (例如 3.4.1)。同时提供历史版本 htk 下载地址
1.注册账号,下载 htk
2.解压 htk 文件,放入项目根目录的 tools 文件夹中, 以 htk 文件夹名称放入
3.注意: 如果您下载的是 3.4.1 或者更高版本, 需要进入 HTKLib/HRec.c 文件中, 修改 1626 行和 1650 行, 即把以下两行的 dur<=0 都修改为 dur<0,如下所示:
以htk3.4.1版本举例: (1)第1626行: if (dur<=0 && labid != splabid) HError(8522,"LatFromPaths: Align have dur<=0"); 修改为: if (dur<0 && labid != splabid) HError(8522,"LatFromPaths: Align have dur<0");(2)1650行: if (dur<=0 && labid != splabid) HError(8522,"LatFromPaths: Align have dur<=0 ");
修改为: if (dur<0 && labid != splabid) HError(8522,"LatFromPaths: Align have dur<0 ");4.编译: 详情参见解压后的 htk 中的 README 文件(如果未编译, 则无法正常运行)
安装 ParallelWaveGAN: 参见官方地址:按照该官方链接的安装流程,直接在项目的根目录下 git clone ParallelWaveGAN 项目并且安装相关依赖即可。
安装其他依赖: sox, libsndfile等
2.预训练模型
预训练模型 ERNIE-SAT 的模型如下所示:
ERNIE-SAT_ZH
ERNIE-SAT_EN
ERNIE-SAT_ZH_and_EN
创建 pretrained_model 文件夹,下载上述 ERNIE-SAT 预训练模型并将其解压:
mkdir pretrained_model cd pretrained_model tar -zxvf model-ernie-sat-base-en.tar.gz tar -zxvf model-ernie-sat-base-zh.tar.gz tar -zxvf model-ernie-sat-base-en_zh.tar.gz
3.下载
本项目使用 parallel wavegan 作为声码器(vocoder):
pwg_aishell3_ckpt_0.5.zip
创建 download 文件夹,下载上述预训练的声码器(vocoder)模型并将其解压:
mkdir download cd download unzip pwg_aishell3_ckpt_0.5.zip
本项目使用 FastSpeech2 作为音素(phoneme)的持续时间预测器:
fastspeech2_conformer_baker_ckpt_0.5.zip 中文场景下使用
fastspeech2_nosil_ljspeech_ckpt_0.5.zip 英文场景下使用
下载上述预训练的 fastspeech2 模型并将其解压
cd download unzip fastspeech2_conformer_baker_ckpt_0.5.zip unzip fastspeech2_nosil_ljspeech_ckpt_0.5.zip
4.推理
本项目当前开源了语音编辑、个性化语音合成、跨语言语音合成的推理代码,后续会逐步开源。 注:当前英文场下的合成语音采用的声码器默认为 vctk_parallel_wavegan.v1.long, 可在该链接中找到; 若 use_pt_vocoder 参数设置为 False,则英文场景下使用 paddle 版本的声码器。
我们提供特定音频文件, 以及其对应的文本、音素相关文件:
prompt_wav: 提供的音频文件
prompt/dev: 基于上述特定音频对应的文本、音素相关文件
prompt_wav ├── p299_096.wav # 样例语音文件1 ├── p243_313.wav # 样例语音文件2 └── ...
prompt/dev ├── text # 样例语音对应文本 ├── wav.scp # 样例语音路径 ├── mfa_text # 样例语音对应音素 ├── mfa_start # 样例语音中各个音素的开始时间 └── mfa_end # 样例语音中各个音素的结束时间
--am声学模型格式符合 {modelname}{dataset}--am_config,--am_checkpoint,--am_stat和--phones_dict是声学模型的参数,对应于 fastspeech2 预训练模型中的 4 个文件。--voc声码器(vocoder)格式是否符合 {modelname}{dataset}--voc_config,--voc_checkpoint,--voc_stat是声码器的参数,对应于 parallel wavegan 预训练模型中的 3 个文件。--lang对应模型的语言可以是zh或en。--ngpu要使用的 GPU 数,如果 ngpu==0,则使用 cpu。--model_name模型名称--uid特定提示(prompt)语音的 id--new_str输入的文本(本次开源暂时先设置特定的文本)--prefix特定音频对应的文本、音素相关文件的地址--source_lang, 源语言--target_lang, 目标语言--output_name, 合成语音名称--task_name, 任务名称, 包括:语音编辑任务、个性化语音合成任务、跨语言语音合成任务--use_pt_vocoder, 英文场景下是否使用 torch 版本的 vocoder, 默认情况下为 False; 设置为 False 则在英文场景下使用 paddle 版本 vocoder
运行以下脚本即可进行实验
sh run_sedit_en.sh # 语音编辑任务(英文) sh run_gen_en.sh # 个性化语音合成任务(英文) sh run_clone_en_to_zh.sh # 跨语言语音合成任务(英文到中文的语音克隆)
新闻资讯
关注人脸、文字识别、关注ai智能未来- 百度离线活体检测精度怎么样 2024-01-16
- 百度云ocr私有化部署是如何计费的 2024-01-16
- 百度智能云AI作画高级版API全方面升级 2024-01-16
- 房产证OCR识别算法,快来免费试用! 2024-01-16
- 曦灵数字人平台重磅升级,限时邀测 2024-01-16
- 百度云文档解析api接口 2024-01-16

